
Both AI and machine learning (ML) technologies have developing rapidly in recent decades, especially in the application of deep learning (DL) in computer vision (CV). The objective of ML and DL implementation is to have computers perform labor-intensive repetitive tasks while simultaneously “learning” from those tasks. Both ML and DL fall within the scope of empirical study, where data is the most essential component. In vision-based Structural Health Monitoring (SHM), using images as data media is currently an active research direction. Structural images obtained from reconnaissance efforts or daily life are playing an increasing role as the success of ML and DL is contingent on the volume of data media available. The expectation is that eventually computers will be able to realize autonomous recognition of structural damage in daily life—under service conditions—or after an extreme event—a large earthquake or extreme wind. Until now, vision-based SHM applications have not fully benefited from the data-driven CV technologies, even as interest on this topic is ever increasing. Its application to structural engineering has been hamstrung mainly due to two factors: (1) the lack of a general automated detection principles or frameworks based on domain knowledge; and (2) the lack of benchmark datasets with well-labeled large amounts of data.
To address the above-mentioned two drawbacks, this report describes recent effort to build a large-scale open-sourced structural image database: the PEER (Pacific Earthquake Engineering Research Center) Hub ImageNet (PHI-Net or Φ-Net). As of November 2019, this Φ-Net dataset contains 36,413 images with multiple attributes for the following baseline recognition tasks: scene level classification, structural component type identification, crack existence check, and damage-level detection. The Φ-Net dataset uses a hierarchy-tree framework for automated structural detection tasks founded on past experiences from reconnaissance efforts for post-earthquakes and other hazards. Through a tree-branch mechanism, each structural image can be clustered into several sub-categories representing detection tasks. This acts as a sort of a filtering operation to decrease the complexity of the problem and improve the performance of the automated applications of the algorithms. To the best of the authors’ knowledge, until now there is no open-sourced structural image dataset with multi-attribute labels and this volume of images in the vision-based SHM area. It is believed that this image dataset and its corresponding detection tasks and framework will provide the necessary benchmark for future studies of DL in vision-based SHM.
Framework of Φ-Net
Analogous to the classification and localization tasks in the ImageNet challenge, the goal of the Φ-Net framework was to construct similar recognition tasks, designed for structural damage recognition and evaluation. Based on past experiences from reconnaissance efforts (Sezen et al. [2003]; Li and Mosalam [2013]; Mosalam et al. [2014]; and Koch et al. [2015]), several issues affect the safety of structures post-event: the type of damaged component, the severity of damage in the component, and the type of damage. Because images collected from reconnaissance efforts broadly vary, including, different distances from objects, camera angles, and emphasized targets, it is useful to cluster these issues into different levels. That is, images taken from a very close distance or only containing part of the component belong to the pixel level; major targets in images such as single or multiple components belong to the object level, and images containing most of the structure belong to the structural level. Moreover, the corresponding evaluation criteria will be different for different levels: that is, images in the pixel level are more related to the material type and damage status; images on the structural level are more related to the structural type and failure status.
Herein, we proposed herein is a new processing framework with a hierarchy-tree structure shown in Figure 1, where images are classified as follows: (1) a raw image is clustered to different scene levels; (2) according to its level, corresponding recognition tasks are applied layer by layer following this hierarchy structure; and (3) each node is seen as one recognition task or a classifier, and the output of each node is seen as a characteristic or feature of the image to help with further analysis and decision making if required.
In the current Φ-Net, we designed the following eight benchmark classification tasks:
- three-class classification for scene level;
- binary classification for damage state;
- binary classification for spalling condition (material loss);
- binary classification for material type;
- three-class classification for collapse mode;
- four-class classification for component type;
- four-class classification for damage level and
- four-class classification for damage type.
The proposed framework with a hierarchy-tree structure is depicted in Figure 1, where grey boxes represent the detection tasks for the corresponding attributes, white boxes within the dashed lines are possible labels of the attributes to be chosen in each task, and ellipsis in boxes represent other choices or conditions. In the detection procedure, one starts from a root leaf where recognition tasks are conducted layer by layer and node by node (grey box) until another leaf node. The output label of each node describes a structural attribute. Each structural image may have multiple attributes, i.e., one image can be categorized as being at the pixel level, concrete, damaged state, etc. In the terminology of CV, this is considered a multi-attribute (multi-label) classification problem. Given that this is a pilot study, these attributes are treated independently at this stage. More extensions such as the multi-label version of Φ-Net will be updated in future studies.
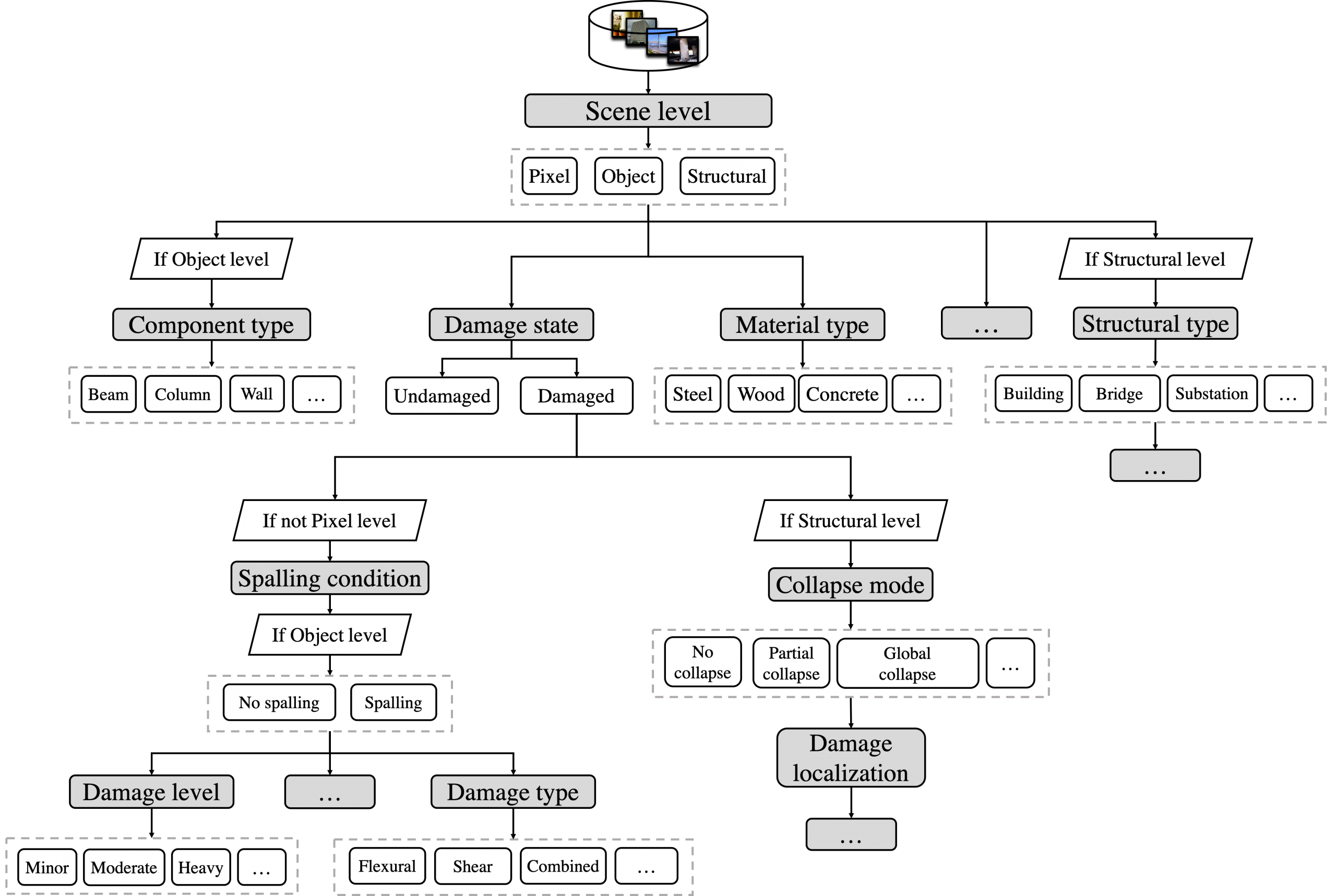
Figure 1 Framework of Φ-Net
Reference
1. Gao, Y., & Mosalam, K. M. (2019). PEER Hub ImageNet (Φ-Net): A Large-Scale Multi-Attribute Benchmark Dataset of Structural Images, PEER Report No.2019/07, Pacific Earthquake Engineering Research Center, University of California, Berkeley, CA.
2. Gao Y., & Mosalam K.M. (2018). Deep Transfer Learning for Image-based Structural Damage Recognition, Comput-Aided Civil and Infrastructure Engineering, 33(9): 748-768.
3. Sezen H., Whittaker A.S., Elwood K.J., & Mosalam K.M. (2003). Performance of reinforced concrete buildings during the August 17, 1999 Kocaeli, Turkey earthquake, and seismic design and construction practice in Turkey, Eng. Struct., 25(1) 103–14.
4. Li, B., & Mosalam, K. M. (2012). Seismic performance of reinforced-concrete stairways during the 2008 Wenchuan earthquake. Journal of Performance of Constructed Facilities, 27(6), 721-730.
5. Mosalam K.M., Takhirov S.M., & Park S. (2014). Applications of laser scanning to structures in laboratory tests and field surveys, Struct Control Hlth, 21(1): 115–34.
6. Koch C., Georgieva K., Kasireddy V., Akinci B., & Fieguth P. (2015). A review on computer vision-based defect detection and condition assessment of concrete and asphalt civil infrastructure, Adv. Eng. Inform., 29(2): 196–210.
![]()